| Age | Commit message (Collapse) | Author |
|---|
|
during coin selection
71d1d13627ccd27319f347e2d8167c8fe8a433f4 test: add unit test for AvailableCoins (josibake)
da03cb41a4ce15ebceee7fa4a4fdd2d3602fe284 test: functional test for new coin selection logic (josibake)
438e04845bf3302b7f459a50e88a1b772527f1e6 wallet: run coin selection by `OutputType` (josibake)
77b07072061c59f50c69be29fbcddf0d433e1077 refactor: use CoinsResult struct in SelectCoins (josibake)
2e67291ca3ab2d8f498fa910738ca655fde11c5e refactor: store by OutputType in CoinsResult (josibake)
Pull request description:
# Concept
Following https://github.com/bitcoin/bitcoin/pull/23789, Bitcoin Core wallet will now generate a change address that matches the payment address type. This improves privacy by not revealing which of the outputs is the change at the time of the transaction in scenarios where the input address types differ from the payment address type. However, information about the change can be leaked in a later transaction. This proposal attempts to address that concern.
## Leaking information in a later transaction
Consider the following scenario:
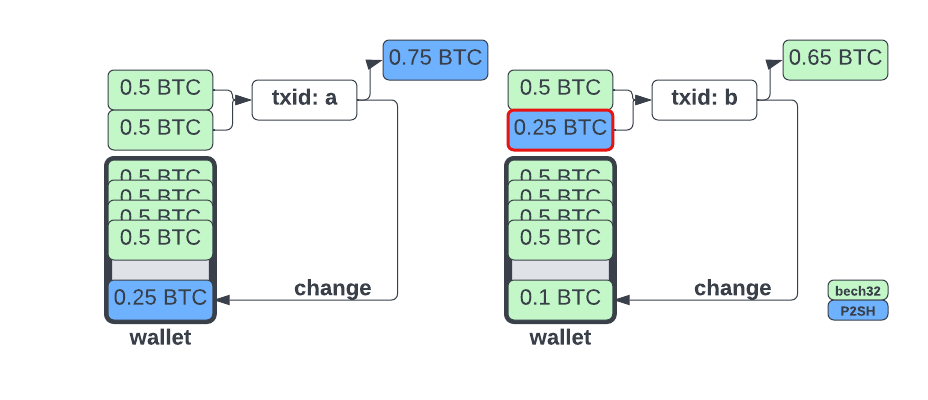
1. Alice has a wallet with bech32 type UTXOs and pays Bob, who gives her a P2SH address
2. Alice's wallet generates a P2SH change output, preserving her privacy in `txid: a`
3. Alice then pays Carol, who gives her a bech32 address
4. Alice's wallet combines the P2SH UTXO with a bech32 UTXO and `txid: b` has two bech32 outputs
From a chain analysis perspective, it is reasonable to infer that the P2SH input in `txid: b` was the change from `txid: a`. To avoid leaking information in this scenario, Alice's wallet should avoid picking the P2SH output and instead fund the transaction with only bech32 Outputs. If the payment to Carol can be funded with just the P2SH output, it should be preferred over the bech32 outputs as this will convert the P2SH UTXO to bech32 UTXOs via the payment and change outputs of the new transaction.
**TLDR;** Avoid mixing output types, spend non-default `OutputTypes` when it is economical to do so.
# Approach
`AvailableCoins` now populates a struct, which makes it easier to access coins by `OutputType`. Coin selection tries to find a funding solution by each output type and chooses the most economical by waste metric. If a solution can't be found without mixing, coin selection runs over the entire wallet, allowing mixing, which is the same as the current behavior.
I've also added a functional test (`test/functional/wallet_avoid_mixing_output_types.py`) and unit test (`src/wallet/test/availablecoins_tests.cpp`.
ACKs for top commit:
achow101:
re-ACK 71d1d13627ccd27319f347e2d8167c8fe8a433f4
aureleoules:
ACK 71d1d13627ccd27319f347e2d8167c8fe8a433f4.
Xekyo:
reACK 71d1d13627ccd27319f347e2d8167c8fe8a433f4 via `git range-diff master 6530d19 71d1d13`
LarryRuane:
ACK 71d1d13627ccd27319f347e2d8167c8fe8a433f4
Tree-SHA512: 2e0716efdae5adf5479446fabc731ae81d595131d3b8bade98b64ba323d0e0c6d964a67f8c14c89c428998bda47993fa924f3cfca1529e2bd49eaa4e31b7e426
|
|
|
|
Run coin selection on each OutputType separately, choosing the best
solution according to the waste metric.
This is to avoid mixing UTXOs that are of different OutputTypes,
which can hurt privacy.
If no single OutputType can fund the transaction, then coin selection
considers the entire wallet, potentially mixing (current behavior).
This is done inside AttemptSelection so that all OutputTypes are
considered at each back-off in coin selection.
|
|
Pass the whole CoinsResult struct to SelectCoins instead of only a
vector. This means we now have to remove preselected coins from each
OutputType vector and shuffle each vector individually.
Pass the whole CoinsResult struct to AttemptSelection. This involves
moving the logic in AttemptSelection to a newly named function,
ChooseSelectionResult. This will allow us to run ChooseSelectionResult
over each OutputType in a later commit. This ensures the backoffs work
properly.
Update unit and bench tests to use CoinResult.
|
|
They are needed, otherwise the next commit will not compile
|
|
|
|
connect it to CreateTransaction and GetNewDestination
111ea3ab711414236f8678566a7884d48619b2d8 wallet: refactor GetNewDestination, use BResult (furszy)
22351725bc4c5eb63ee45f607374bbf2d76e2b8c send: refactor CreateTransaction flow to return a BResult<CTransactionRef> (furszy)
198fcca162f4d2f877feab485e629ff89818ff56 wallet: refactor, include 'FeeCalculation' inside 'CreatedTransactionResult' (furszy)
7a45c33d1f8a758850cf8e7bd6ad508939ba5c0d Introduce generic 'Result' class (furszy)
Pull request description:
Based on a common function signature pattern that we have all around the sources:
```cpp
bool doSomething(arg1, arg2, arg3, arg4, &result_obj, &error_string) {
// do something...
if (error) {
error_string = "something bad happened";
return false;
}
result = goodResult;
return true;
}
```
Introduced a generic class `BResult` that encapsulate the function boolean result, the result object (in case of having it) and, in case of failure, the string error reason.
Obtaining in this way cleaner function signatures and removing boilerplate code:
```cpp
BResult<Obj> doSomething(arg1, arg2, arg3, arg4) {
// do something...
if (error) return "something bad happened";
return goodResult;
}
```
Same cleanup applies equally to the function callers' side as well. There is no longer need to add the error string and the result object declarations before calling the function:
Before:
```cpp
Obj result_obj;
std::string error_string;
if (!doSomething(arg1, arg2, arg3, arg4, result_obj, error_string)) {
LogPrintf("Error: %s", error_string);
}
return result_obj;
```
Now:
```cpp
BResult<Obj> op_res = doSomething(arg1, arg2, arg3, arg4);
if (!op_res) {
LogPrintf("Error: %s", op_res.GetError());
}
return op_res.GetObjResult();
```
### Initial Implementation:
Have connected this new concept to two different flows for now:
1) The `CreateTransaction` flow. --> 7ba2b87c
2) The `GetNewDestination` flow. --> bcee0912
Happy note: even when introduced a new class into the sources, the amount of lines removed is almost equal to added ones :).
Extra note: this work is an extended version (and a decoupling) of the work that is inside #24845 (which does not contain the `GetNewDestination` changes nor the inclusion of the `FeeCalculation` field inside `CreatedTransactionResult`).
ACKs for top commit:
achow101:
ACK 111ea3ab711414236f8678566a7884d48619b2d8
w0xlt:
reACK https://github.com/bitcoin/bitcoin/pull/25218/commits/111ea3ab711414236f8678566a7884d48619b2d8
theStack:
re-ACK 111ea3ab711414236f8678566a7884d48619b2d8
MarcoFalke:
review ACK 111ea3ab711414236f8678566a7884d48619b2d8 🎏
Tree-SHA512: 6d84d901a4cb923727067f25ff64542a40edd1ea84fdeac092312ac684c34e3688a52ac5eb012717d2b73f4cb742b9d78e458eb0e9cb9d6d72a916395be91f69
|
|
d54c5c8b1b1a38b5b38e6878aea0fa8d6c1ad7e9 wallet: use CCoinControl to estimate signature size (S3RK)
a94659c84ee10ac5915eb5a6b654435183d88521 wallet: replace GetTxSpendSize with CalculateMaximumSignedInputSize (S3RK)
Pull request description:
Currently `DummySignTx` and `DummySignInput` use different ways to determine signature size.
This PR unifies the way wallet estimates signature size for various inputs.
Instead of passing boolean flags from calling code the `use_max_sig` is now calculated at the place of signature creation using information available in `CCoinControl`
ACKs for top commit:
achow101:
ACK d54c5c8b1b1a38b5b38e6878aea0fa8d6c1ad7e9
theStack:
Code-review ACK d54c5c8b1b1a38b5b38e6878aea0fa8d6c1ad7e9
Tree-SHA512: e790903ad4683067070aa7dbf7434a1bd142282a5bc425112e64d88d27559f1a2cd60c68d6022feaf6b845237035cb18ece10f6243d719ba28173b69bd99110a
|
|
|
|
reading the filter from disk.
e734228d8585c0870c71ce8ba8c037f8cf8b249a Update GCSFilter benchmarks (Calvin Kim)
aee9a8140b3a58b744766f9e89572f1d953a808b Add GCSFilterDecodeSkipCheck benchmark (Patrick Strateman)
299023c1d9962628d158fac0306f8531506a0123 Add GCSFilterDecode and GCSBlockFilterGetHash benchmarks. (Patrick Strateman)
b0a53d50d9142bed51a8372eeb848816bfa94da8 Make sanity check in GCSFilter constructor optional (Patrick Strateman)
Pull request description:
This PR picks up the abandoned #19280
BlockFilterIndex was depending on `GolombRiceDecode()` during the filter decode to sanity check that the filter wasn't corrupt. However, we can check for corruption by ensuring that the encoded blockfilter's hash matches up with the one stored in the index database.
Benchmarks that were added in #19280 showed that checking the hash is much faster.
The benchmarks were changed to nanobench and the relevant benchmarks were like below, showing a clear win for the hash check method.
```
| ns/elem | elem/s | err% | ins/elem | bra/elem | miss% | total | benchmark
|--------------------:|--------------------:|--------:|----------------:|---------------:|--------:|----------:|:----------
| 531.40 | 1,881,819.43 | 0.3% | 3,527.01 | 411.00 | 0.2% | 0.01 | `DecodeCheckedGCSFilter`
| 258,220.50 | 3,872.66 | 0.1% | 2,990,092.00 | 586,706.00 | 1.7% | 0.01 | `DecodeGCSFilter`
| 13,036.77 | 76,706.09 | 0.3% | 64,238.24 | 513.04 | 0.2% | 0.01 | `BlockFilterGetHash`
```
ACKs for top commit:
mzumsande:
Code Review ACK e734228d8585c0870c71ce8ba8c037f8cf8b249a
theStack:
Code-review ACK e734228d8585c0870c71ce8ba8c037f8cf8b249a
stickies-v:
ACK e734228d8585c0870c71ce8ba8c037f8cf8b249a
ryanofsky:
Code review ACK e734228d8585c0870c71ce8ba8c037f8cf8b249a, with caveat that I mostly paid attention to the main code, not the changes to the benchmark. Only changes since last review were changes to the benchmark code.
Tree-SHA512: 02b86eab7b554e1a57a15b17a4d6d71faa91b556c637b0da29f0c9ee76597a110be8e3b4d0c158d4cab04af0623de18b764837be0ec2a72afcfe1ad9c78a83c6
|
|
e673d8b475995075b696208386c9e45ae7ca3e20 bench: Enable loading benchmarks depending on what's compiled (Andrew Chow)
4af3547ebac672a2d516e8696fd3580a766c27eb bench: Use mock wallet database for wallet loading benchmark (Andrew Chow)
49910f255f77e14fccf189353d188efac00d1445 sqlite: Use in-memory db instead of temp for mockdb (Andrew Chow)
a1080802f8d7c3d1251ec6f2be33031f568deafa walletdb: Create a mock database of specific type (Andrew Chow)
7c0d34476df446e3825198b27c6f62bba4c0b974 bench: reduce the number of txs in wallet for wallet loading bench (Andrew Chow)
f85b54ed27bd6eddb1e7035db02d542575b3ab24 bench: Add transactions directly instead of mining blocks (Andrew Chow)
d94244c4bf37365272a16eb2ce6517605b4c8a47 bench: reduce number of epochs for wallet loading benchmark (Andrew Chow)
817c051364208d3f9e7e2af5700bd2bee5c9f303 bench: use unsafesqlitesync in wallet loading benchmark (Andrew Chow)
9e404a98312d73c969adf4f8e87aad1ac4b3029d bench: Remove minEpochIterations from wallet loading benchmark (Andrew Chow)
Pull request description:
`minEpochIterations` is probably unnecessary to set, so removing it makes the runtime much faster.
ACKs for top commit:
Rspigler:
tACK e673d8b475995075b696208386c9e45ae7ca3e20
furszy:
Code review ACK e673d8b4, nice PR.
glozow:
Concept ACK e673d8b475995075b696208386c9e45ae7ca3e20. For each commit, verified that there was a performance improvement without negating the purpose of the bench, and made some effort to verify that the code is correct.
Tree-SHA512: 9337352ef846cf18642d5c14546c5abc1674b4975adb5dc961a1a276ca91f046b83b7a5e27ea6cd26264b96ae71151e14055579baf36afae7692ef4029800877
|
|
|
|
|
|
call sites
d273e53b6e2cabd91a83f0ff0f9b6cfe1815b637 bench/rpc_mempool: Create ChainTestingSetup, use its CTxMemPool (Carl Dong)
020caba3df727ae8ede50eace86ae76971c0fea1 bench: Use existing CTxMemPool in TestingSetup (Carl Dong)
86e732def3983f99ec84b59375615bedcdc0e664 scripted-diff: test: Use CTxMemPool in TestingSetup (Carl Dong)
213457e170ce41a0b26c644aa010111df36414a6 test/policyestimator: Use ChainTestingSetup's CTxMemPool (Carl Dong)
319f0ceeeb25f28e027fc41be2755092dc5365b4 rest/getutxos: Don't construct empty mempool (Carl Dong)
03574b956a274207ba90591781e0914609225136 tree-wide: clang-format CTxMemPool references (Carl Dong)
Pull request description:
This is part of the `libbitcoinkernel` project: #24303, https://github.com/bitcoin/bitcoin/projects/18
This PR reduces the number of call sites where we explicitly construct CTxMemPool. This is done in preparation for later PRs which decouple the mempool module from `ArgsManager`, eventually all of libbitcoinkernel will be decoupled from `ArgsManager`.
The changes in this PR:
- Allows us to have less code churn as we modify `CTxMemPool`'s constructor in later PRs
- In many cases, we can make use of existing `CTxMemPool` instances, getting rid of extraneous constructions
- In other cases, we construct a `ChainTestingSetup` and use the `CTxMemPool` there, so that we can rely on the logic in `setup_common` to set things up correctly
## Notes for Reviewers
### A note on using existing mempools
When evaluating whether or not it's appropriate to use an existing mempool in a `*TestingSetup` struct, the key is to make sure that the mempool has the same lifetime as the `*TestingSetup` struct.
Example 1: In [`src/fuzz/tx_pool.cpp`](https://github.com/bitcoin/bitcoin/blob/b4f686952a60bbadc7ed2250651d0d6af0959f4d/src/test/fuzz/tx_pool.cpp), the `TestingSetup` is initialized in `initialize_tx_pool` and lives as a static global, while the `CTxMemPool` is in the `tx_pool_standard` fuzz target, meaning that each time the `tx_pool_standard` fuzz target gets run, a new `CTxMemPool` is created. If we were to use the static global `TestingSetup`'s CTxMemPool we might run into problems since its `CTxMemPool` will carry state between subsequent runs. This is why we don't modify `src/fuzz/tx_pool.cpp` in this PR.
Example 2: In [`src/bench/mempool_eviction.cpp`](https://github.com/bitcoin/bitcoin/blob/b4f686952a60bbadc7ed2250651d0d6af0959f4d/src/bench/mempool_eviction.cpp), we see that the `TestingSetup` is in the same scope as the constructed `CTxMemPool`, so it is safe to use its `CTxMemPool`.
### A note on checking `CTxMemPool` ctor call sites
After the "tree-wide: clang-format CTxMemPool references" commit, you can find all `CTxMemPool` ctor call sites with the following command:
```sh
git grep -E -e 'make_unique<CTxMemPool>' \
-e '\bCTxMemPool\s+[^({;]+[({]' \
-e '\bCTxMemPool\s+[^;]+;' \
-e '\bnew\s+CTxMemPool\b'
```
At the end of the PR, you will find that there are still quite a few call sites that we can seemingly get rid of:
```sh
$ git grep -E -e 'make_unique<CTxMemPool>' -e '\bCTxMemPool\s+[^({;]+[({]' -e '\bCTxMemPool\s+[^;]+;' -e '\bnew\s+CTxMemPool\b'
# rearranged for easier explication
src/init.cpp: node.mempool = std::make_unique<CTxMemPool>(node.fee_estimator.get(), mempool_check_ratio);
src/test/util/setup_common.cpp: m_node.mempool = std::make_unique<CTxMemPool>(m_node.fee_estimator.get(), 1);
src/rpc/mining.cpp: CTxMemPool empty_mempool;
src/test/util/setup_common.cpp: CTxMemPool empty_pool;
src/bench/mempool_stress.cpp: CTxMemPool pool;
src/bench/mempool_stress.cpp: CTxMemPool pool;
src/test/fuzz/rbf.cpp: CTxMemPool pool;
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/validation_load_mempool.cpp: CTxMemPool pool{};
src/txmempool.h: /** Create a new CTxMemPool.
```
Let's break them down one by one:
```
src/init.cpp: node.mempool = std::make_unique<CTxMemPool>(node.fee_estimator.get(), mempool_check_ratio);
src/test/util/setup_common.cpp: m_node.mempool = std::make_unique<CTxMemPool>(m_node.fee_estimator.get(), 1);
```
Necessary
-----
```
src/rpc/mining.cpp: CTxMemPool empty_mempool;
src/test/util/setup_common.cpp: CTxMemPool empty_pool;
```
These are fixed in #25223 where we stop requiring the `BlockAssembler` to have a `CTxMemPool` if it's not going to consult it anyway (as is the case in these two call sites)
-----
```
src/bench/mempool_stress.cpp: CTxMemPool pool;
src/bench/mempool_stress.cpp: CTxMemPool pool;
```
Fixed in #24927.
-----
```
src/test/fuzz/rbf.cpp: CTxMemPool pool;
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/validation_load_mempool.cpp: CTxMemPool pool{};
```
These are all cases where we don't want the `CTxMemPool` state to persist between runs, see the previous section "A note on using existing mempools"
-----
```
src/txmempool.h: /** Create a new CTxMemPool.
```
It's a comment (someone link me to a grep that understands syntax plz thx)
ACKs for top commit:
laanwj:
Code review ACK d273e53b6e2cabd91a83f0ff0f9b6cfe1815b637
Tree-SHA512: c4ff3d23217a7cc4a7145defc7b901725073ef73bcac3a252ed75f672c87e98ca0368d1d8c3f606b5b49f641e7d8387d26ef802141b650b215876f191fb6d5f9
|
|
This is correct because:
- The ChainTestingSetup is constructed before the call to bench.run(...)
- All the runs are performed on the same mempool
|
|
|
|
transactions, fix #24634 bug
d2f8f1b307b056d1a54fb02a99da2cb664570904 use testing setup mempool in ComplexMemPool bench (glozow)
aecc332a71037812b7334a0ea72d0bcf8160c12f create and use mempool transactions using real coins in MempoolCheck (glozow)
21187506311d1703d2bca21ccc17c3a921454b70 [test util] to populate mempool with random transactions/packages (glozow)
5374dfc4e3da0e6a76f33b42966b4acf446233dc [test util] use -checkmempool for TestingSetup mempool check ratio (glozow)
d7d9c7b2661d7f4292bfcdc389a806028fa2207d [test util] add chain name to TestChain100Setup ctor (glozow)
Pull request description:
Fixes #24634 by using the `testing_setup`'s actual mempool rather than a locally-declared mempool for running `check()`.
Also creates a test utility for populating the mempool with a bunch of random transactions. I imagine this could be useful in other places as well; it was necessary here because we needed the mempool to contain transactions *spending coins available in the current chainstate*. The existing `CreateOrderedCoins()` is insufficient because it creates coins out of thin air.
Also implements the separate suggestion to use the `TestingSetup` mempool in `ComplexMemPool` bench.
ACKs for top commit:
laanwj:
Code review ACK d2f8f1b307b056d1a54fb02a99da2cb664570904
Tree-SHA512: 44ab5a9e55b126b5a5bc33f05fbad1380b9c43c84736c7cf487be025e0e3f5d75216ccf5a3088b0935da817e3dacfba99d2885f75bcb6e7eaa24cd20a82c24c8
|
|
|
|
|
|
|
|
Element count used in the GCSFilter benchmarks are increased to 100,000
from 10,000. Testing the benchmarks with different element counts showed
that a filter with 100,000 elements resulted in the same ns/op. This
this a desirable thing to have as it allows us to reason about how long
a single filter element takes to process, letting us easily calculate
how long a filter with N elements (where N > 100,000) would take to
process.
GCSFilterConstruct benchmark is now called without batch. This makes
intra-bench results more intuitive as all benchmarks are in ns/op
instead of a custom unit. There are no downsides to this change as
testing showed that there is no observable difference in error rates
in the benchmarks when calling without batch.
|
|
This benchmark allows us to compare the differences between doing the
sanity check for corruption via GolombRiceDecode() vs checking the hash
of the encoded block filter.
|
|
All of the benchmarks are standardized on the BASIC filter parameters
so we can compare between all the benchmarks. All the GCS
benchmarks are renamed to have "GCS" as the prefix.
|
|
Previously in COutput, effective_value was initialized as the absolute
value of the txout, and fee as 0. effective_value along with fee were
calculated outside of the COutput constructor and set after the
object had been initialized. These changes will allow either the fee
or the feerate to be passed in a COutput constructor. If either are
provided, fee and effective_value are calculated and set in the
constructor. As a result, AvailableCoins also needs to be passed the
feerate when utxos are being spent. When balance is calculated or the
coins are being listed and feerate is neither available nor required,
AvailableCoinsListUnspent is used instead, which runs AvailableCoins
while providing the default value for feerate. Unit tests for the
calculation of effective value have also been added.
|
|
|
|
This is customary for UNIX-style arguments, and more consistent with our
other tools
|
|
The benchmarks are run as part of `make check` for a minimum sanity
check. The actual results are being ignored. So only run them for one
iteration.
This makes the `bench_bitcoin` part take 2m00 instead of 5m20 here.
Which is still too long (imo), but this needs to be solved in the
`WalletLoading*` benchmarks which take that long per iteration.
|
|
Add descriptor wallet benchmark only if sqlite is compiled. Add legacy
wallet benchmark only if bdb is compiled.
|
|
Using in-memory only databases speeds up the benchmark, at the cost of
real world accuracy.
|
|
5e61532e72c1021fda9c7b213bd9cf397cb3a802 util: optimizes HexStr (Martin Leitner-Ankerl)
4e2b99f72a90b956f3050095abed4949aff9b516 bench: Adds a benchmark for HexStr (Martin Leitner-Ankerl)
67c8411c37b483caa2fe3f7f4f40b68ed2a9bcf7 test: Adds a test for HexStr that checks all 256 bytes (Martin Leitner-Ankerl)
Pull request description:
In my benchmark, this rewrite improves runtime 27% (g++) to 46% (clang++) for the benchmark `HexStrBench`:
g++ 11.2.0
| ns/byte | byte/s | err% | ins/byte | cyc/byte | IPC | bra/byte | miss% | total | benchmark
|--------------------:|--------------------:|--------:|----------------:|----------------:|-------:|---------------:|--------:|----------:|:----------
| 0.94 | 1,061,381,310.36 | 0.7% | 12.00 | 3.01 | 3.990 | 1.00 | 0.0% | 0.01 | `HexStrBench` master
| 0.68 | 1,465,366,544.25 | 1.7% | 6.00 | 2.16 | 2.778 | 1.00 | 0.0% | 0.01 | `HexStrBench` branch
clang++ 13.0.1
| ns/byte | byte/s | err% | ins/byte | cyc/byte | IPC | bra/byte | miss% | total | benchmark
|--------------------:|--------------------:|--------:|----------------:|----------------:|-------:|---------------:|--------:|----------:|:----------
| 0.80 | 1,244,713,415.92 | 0.9% | 10.00 | 2.56 | 3.913 | 0.50 | 0.0% | 0.01 | `HexStrBench` master
| 0.43 | 2,324,188,940.72 | 0.2% | 4.00 | 1.37 | 2.914 | 0.25 | 0.0% | 0.01 | `HexStrBench` branch
Note that the idea for this change comes from denis2342 in #23364. This is a rewrite so no unaligned accesses occur.
Also, the lookup table is now calculated at compile time, which hopefully makes the code a bit easier to review.
ACKs for top commit:
laanwj:
Code review ACK 5e61532e72c1021fda9c7b213bd9cf397cb3a802
aureleoules:
tACK 5e61532e72c1021fda9c7b213bd9cf397cb3a802.
theStack:
ACK 5e61532e72c1021fda9c7b213bd9cf397cb3a802 🚤
Tree-SHA512: 40b53d5908332473ef24918d3a80ad1292b60566c02585fa548eb4c3189754971be5a70325f4968fce6d714df898b52d9357aba14d4753a8c70e6ffd273a2319
|
|
Reason:
A swap must not fail; when a class has a swap member function, it should be declared noexcept.
https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#c84-a-swap-function-must-not-fail
|
|
36f814c0e84d009c0e0aa26981a20ac4cf338a85 [netgroupman] Remove NetGroupManager::GetAsmap() (John Newbery)
4709fc2019e27e74be02dc5fc123b9f6f46d7990 [netgroupman] Move asmap checksum calculation to NetGroupManager (John Newbery)
1b978a7e8c71dcc1501705022e66f6779c8c4528 [netgroupman] Move GetMappedAS() and GetGroup() logic to NetGroupManager (John Newbery)
ddb4101e6377a998b7c598bf52217b47698ddec9 [net] Only use public CNetAddr functions and data in GetMappedAS() and GetGroup() (John Newbery)
6b2268162e96bc4fe1a3ebad454996b1d3d4615c [netgroupman] Add GetMappedAS() and GetGroup() (John Newbery)
19431560e3e1124979c60f39eca9429c4a0df29f [net] Move asmap into NetGroupManager (John Newbery)
17c24d458042229e00dd4e0b75a32e593be29564 [init] Add netgroupman to node.context (John Newbery)
9b3836710b8160d212aacd56154938e5bb4b26b7 [build] Add netgroup.cpp|h (John Newbery)
Pull request description:
The asmap data is currently owned by addrman, but is used by both addrman and connman. #22791 made the data const and private (so that it can't be updated by other components), but it is still passed out of addrman as a reference to const, and used by `CNetAddress` to calculate the group and AS of the net address.
This RFC PR proposes to move all asmap data and logic into a new `NetGroupManager` component. This is initialized at startup, and the client components addrman and connman simply call `NetGroupManager::GetGroup(const CAddress&)` and `NetGroupManager::GetMappedAS(const CAddress&)` to get the net group and AS of an address.
ACKs for top commit:
mzumsande:
Code Review ACK 36f814c0e84d009c0e0aa26981a20ac4cf338a85
jnewbery:
CI failure seems spurious. I rebased onto latest master to trigger a new CI run, but whilst I was doing that, mzumsande ACKed https://github.com/bitcoin/bitcoin/commit/36f814c0e84d009c0e0aa26981a20ac4cf338a85, so I've reverted to that.
dergoegge:
Code review ACK 36f814c0e84d009c0e0aa26981a20ac4cf338a85
Tree-SHA512: 244a89cdfd720d8cce679eae5b7951e1b46b37835fccb6bdfa362856761bb110e79e263a6eeee8246140890f3bee2850e9baa7bc14a388a588e0e29b9d275175
|
|
|
|
|
|
|
|
|
|
|
|
`fHavePruned`
f0a2fb3c5dbf3c4bec7faf934baff3e723734b3f scripted-diff: Rename pindexBestHeader, fHavePruned (Carl Dong)
a4014021258319941716d6338c18667462a06280 Clear fHavePruned in BlockManager::Unload() (Carl Dong)
3308ecd3fc254ee4ef9f803c09f00ba4dc968520 move-mostly: Make fHavePruned a BlockMan member (Carl Dong)
c96524113c48553c4bbad63077a25494eca8159e Clear pindexBestHeader in ChainstateManager::Unload() (Carl Dong)
73eedaaacc3b5f2dd791997109f2f5312a894336 style-only: Miscellaneous whitespace changes (Carl Dong)
0d567daf23c9fcb2d95b38913ee45a8b0ba3b027 move-mostly: Make pindexBestHeader a ChainMan member (Carl Dong)
5d670173a32ccdcb25d3a6bf97317f0ac774e0ed validation: Load pindexBestHeader in ChainMan (Carl Dong)
Pull request description:
Split off from #22564 per Marco's suggestion: https://github.com/bitcoin/bitcoin/pull/22564#issuecomment-1100011503
This is basically the move-mostly parts of #22564. The overall intent is to move mutable globals manually reset by `::UnloadBlockIndex` into appropriate structs such that they are cleared at the appropriate times. Please read #22564's description for more rationale.
In summary , this PR moves:
1. `pindexBestHeader` -> `ChainstateManager::m_best_header`
2. `fHavePruned` -> `BlockManager::m_have_pruned`
ACKs for top commit:
ajtowns:
ACK f0a2fb3c5dbf3c4bec7faf934baff3e723734b3f -- code review only
MarcoFalke:
kirby ACK f0a2fb3c5dbf3c4bec7faf934baff3e723734b3f 😋
Tree-SHA512: 8d161701af81af1ff42da1b22a6bef2f8626e8642146bc9c3b27f3a7cd24f4d691910a2392b188ae058fec0611a17304dd73f60da695f53832d327f73d2fc963
|
|
[META] In the next commit, we move the clearing of fHavePruned to
BlockManager::Unload()
|
|
This is probably unnecessary and just makes it slower.
|
|
|
|
Benchmarks conversion of a full binary block into hex, like it is done in rest.cpp.
|
|
|
|
|
|
|
|
|
|
no behavior changes, since the target is always MIN_CHANGE
|
|
049003fe68a4183f6f20da16f58f10079d1e02df coinselection: Remove COutput operators == and != (Andrew Chow)
f6c39c6adb6cbf9c87f04d3d667701905ef5c0a0 coinselection: Remove CInputCoin (Andrew Chow)
70f31f1a81710aa59e95770de9a84bf58cbce1e8 coinselection: Use COutput instead of CInputCoin (Andrew Chow)
14fbb57b79c664090f6a4e60d7bdfc9759ff4307 coinselection: Add effective value and fees to COutput (Andrew Chow)
f0821230b8de2eec21a869d1edf9e2b9f502de25 moveonly: move COutput to coinselection.h (Andrew Chow)
42e974e15c6deba1d9395a4da9341c9ebec6e8e5 wallet: Remove CWallet and CWalletTx from COutput's constructor (Andrew Chow)
14d04d5ad15ae56df56edee7ca9a202b52037889 wallet: Replace CWalletTx in COutput with COutPoint and CTxOut (Andrew Chow)
0ba4d1916e26e2a5d603edcdb7625463989d25b6 wallet: Provide input bytes to COutput (Andrew Chow)
d51f27d3bb0d6e3ca55bcd23ce53e4fe413a9360 wallet: Store whether a COutput is from the wallet (Andrew Chow)
b799814bbd53736b79495072f3c9e05989a465e8 wallet: Store tx time in COutput (Andrew Chow)
46022953ee2e8113167bafd1fd48a383a578b13c wallet: Remove use_max_sig default value (Andrew Chow)
10379f007fd2c18f4cd24d0a0783d6d929f45556 scripted-diff: Rename COutput member variables (Andrew Chow)
c7c64db41e1718584aa2f30ff27f60ab0966de62 wallet: cleanup COutput constructor (Andrew Chow)
Pull request description:
While working on coin selection code, it occurred to me that `CInputCoin` is really a subset of `COutput` and the conversion of a `COutput` to a `CInputCoin` does not appear to be all that useful. So this PR adds fields that are present in `CInputCoin` to `COutput` and replaces the usage of `CInputCoin` with `COutput`.
`COutput` is also moved to coinselection.h. As part of this move, the usage of `CWalletTx` is removed from `COutput`. It is instead replaced by storing a `COutPoint` and the `CTxOut` rather than the entire `CWalletTx` as coin selection does not really need the full `CWalletTx`. The `CWalletTx` was only used for figuring out whether the transaction containing the output was from the current wallet, and for the transaction's time. These are now parameters to `COutput`'s constructor.
ACKs for top commit:
ryanofsky:
Code review ACK 049003fe68a4183f6f20da16f58f10079d1e02df, just adding comments and removing == operators since last review
w0xlt:
reACK 049003f
Xekyo:
reACK 049003fe68a4183f6f20da16f58f10079d1e02df
Tree-SHA512: 048b4cd620a0415e1d9fe8597257ee4bc64656566e1d28a9bdd147d6d72dc87c3f34a3339fa9ab6acf42c388df7901fc4ee900ccaabc3de790ffad162b544c15
|
|
It is no longer needed as everything it was doing is now done by COutput
|
|
Also rename setPresetCoins to preset_coins
|
